


Yelp is a localized search engine for companies in your area. People talk about their experiences with that company in the form of reviews, which is a great source of information. Customer input can assist in identifying and prioritizing advantages and problems for future business development.
We now have access to a variety of sources thanks to the internet, where people are prepared to share their experiences with various companies and services. We may exploit this opportunity to gather some useful data and generate some actionable intelligence to provide the best possible client experience.
We can collect a substantial portion of primary and secondary data sources, analyze them, and suggest areas for improvement by scraping all of those evaluations. Python has packages that make these activities very simple. We can choose the requests library for web scraping since it performs the job and is very easy to use
By analyzing the website via a web browser, we may quickly understand the structure of the website. Here is the list of possible data variables to collect after researching the layout of the Yelp website:
Reviewer’s name
Review
Date
Star ratings
Restaurant Name
The requests module makes it simple to get files from the internet. The requests module can be installed by following these steps:
pip install requests
To begin, we go to the Yelp website and type in “restaurants near me” in the Chicago, IL area.
We’ll then import all of the necessary libraries and build a panda DataFrame.
import pandas as pd
import time as t
from lxml import html
import requestsreviews_df=pd.DataFrame()
Downloading the HTML page using request.get()
import requests
searchlink= 'https://www.yelp.com/search?find_desc=Restaurants&find_loc=Chicago,+IL'
user_agent = ‘ Enter you user agent here ’
headers = {‘User-Agent’: user_agent}
Get the user agent here
To scrape restaurant reviews for any other location on the same review platform, simply copy and paste the URL. All you have to do is provide a link.
page = requests.get(searchlink, headers = headers)
parser = html.fromstring(page.content)
The Requests.get() will be downloaded in the HTML page. Now we must search the page for the links to various eateries.
businesslink=parser.xpath('//a[@class="biz-name js-analytics-click"]')
links = [l.get('href') for l in businesslink]
Because these links are incomplete, we will need to add the domain name.
u=[]
for link in links:
u.append('https://www.yelp.com'+ str(link))
We now have most of the restaurant titles from the very first page; each page has 30 search results. Let’s go over each page one by one and seek their feedback.
for item in u:
page = requests.get(item, headers = headers)
parser = html.fromstring(page.content)
A div with the class name “review review — with-sidebar” contains the reviews. Let’s go ahead and grab all of these divs.
xpath_reviews = ‘//div[@class=”review review — with-sidebar”]’
reviews = parser.xpath(xpath_reviews)
We would like to scrape the author name, review body, date, restaurant name, and star rating for each review.
for review in reviews:
temp = review.xpath('.//div[contains(@class, "i-stars i- stars--regular")]')
rating = [td.get('title') for td in temp] xpath_author = './/a[@id="dropdown_user-name"]//text()'
xpath_body = './/p[@lang="en"]//text()'
author = review.xpath(xpath_author)
date = review.xpath('.//span[@class="rating-qualifier"]//text()')
body = review.xpath(xpath_body)
heading= parser.xpath('//h1[contains(@class,"biz-page-title embossed-text-white")]')
bzheading = [td.text for td in heading]
For all of these objects, we’ll create a dictionary, which we’ll then store in a pandas data frame.
review_dict = {‘restaurant’ : bzheading,
‘rating’: rating,
‘author’: author,
‘date’: date,
‘Review’: body,
}
reviews_df = reviews_df.append(review_dict, ignore_index=True)
We can now access all of the reviews from a single website. By determining the maximum reference number, you can loop across the pages. A <a> tag with the class name “available-number pagination-links anchor” contains the latest page number.
page_nums = '//a[@class="available-number pagination-links_anchor"]'
pg = parser.xpath(page_nums)max_pg=len(pg)+1
Here we will scrape a total of 23,869 reviews with the aforementioned script, for about 450 eateries and 20-60 reviews for each restaurant.
Let’s launch a jupyter notebook and do some text mining and sentiment analysis.
First, get the libraries you’ll need.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
We will save the data in a file named all.csv.
data=pd.read_csv(‘all.csv’)
Let’s take a look at the data frame’s head and tail.
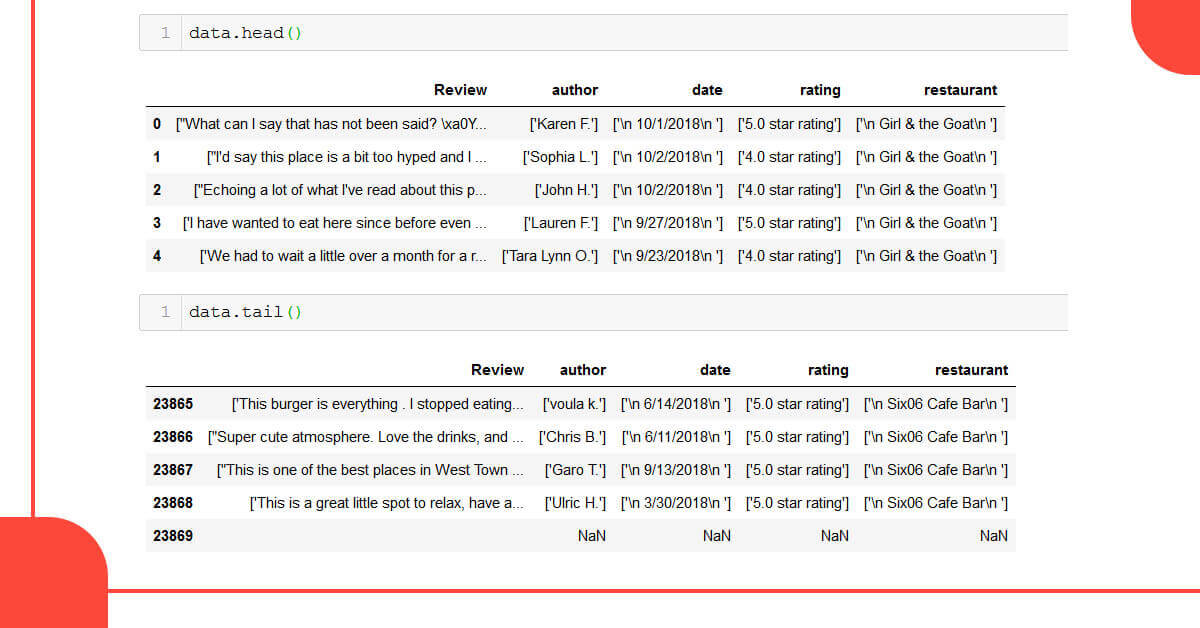
With 5 columns, we get 23,869 records. As can be seen, the data requires formatting. Symbols, tags, and spaces that aren’t needed should be eliminated. There are a few Null/NaN values as well.
Remove all values that are Null/NaN from the data frame.
data.dropna()
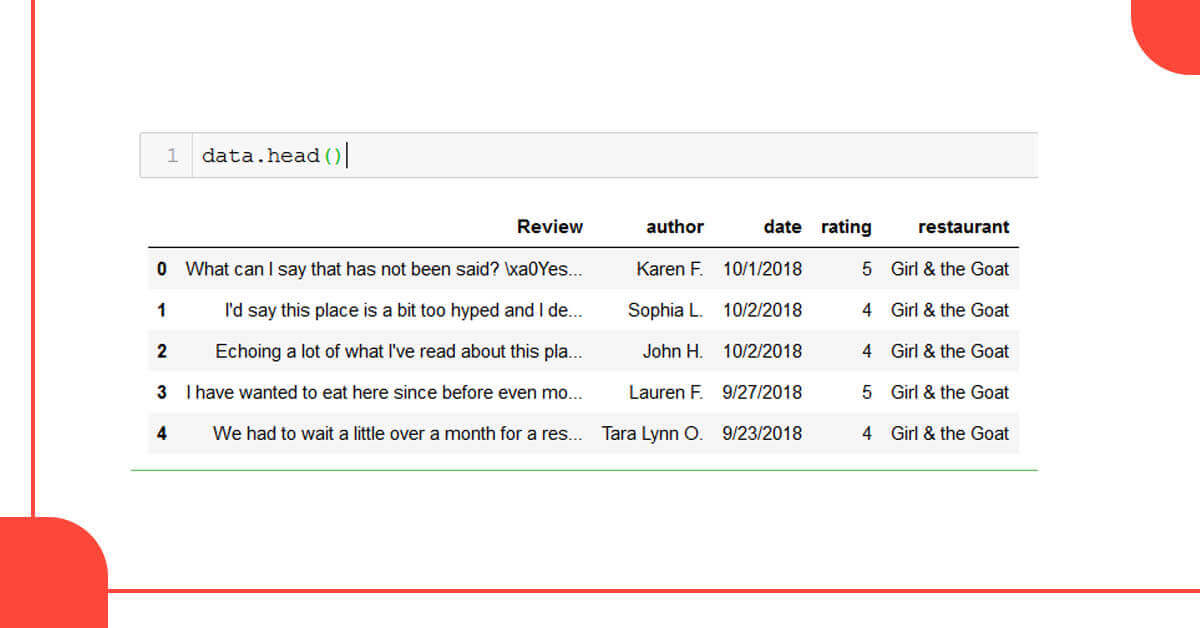
We’ll now eliminate the extraneous symbols and spaces using string slicing.
Read more:- https://www.foodspark.io/how-does-web-scraping-help-in-extracting-yelp-data-and-other-restaurant-reviews/